
仕事で3万行ぐらいあるそこそこ規則的なテキストファイルから任意の文字列を抽出しました。
今後も同じことを何度かやるので備忘録として、完全に個人的なメモです。
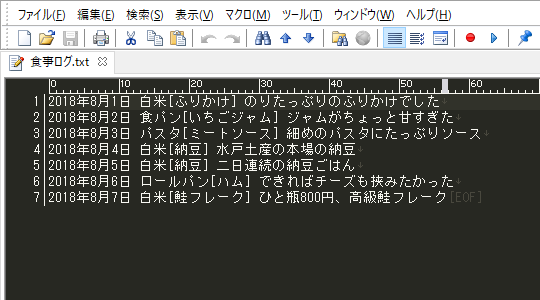
例えばこんな感じのテキストデータから、任意の文字列を抽出したい。
2018年8月1日 白米[ふりかけ] のりたっぷりのふりかけでした 2018年8月2日 食パン[いちごジャム] ジャムがちょっと甘すぎた 2018年8月3日 パスタ[ミートソース] 細めのパスタにたっぷりソース 2018年8月4日 白米[納豆] 水戸土産の本場の納豆 2018年8月5日 白米[納豆] 二日連続の納豆ごはん 2018年8月6日 ロールパン[ハム] できればチーズも挟みたかった 2018年8月7日 白米[鮭フレーク] ひと瓶800円、高級鮭フレーク
食事のログかなんかだと思っていただければ幸い。
日付の後にくるのがその日に摂取した炭水化物、炭水化物の後に角括弧[]で囲まれている部分がその日の炭水化物のトッピングでいわゆる「ご飯の友」、そのうしろがひと言メモという構成。
抽出したいのは白米だった日のご飯の友、ついでに重複する文字列は削除してひとつにしたい。最終的に目標とする形は下のようなもの。
ふりかけ 納豆 鮭フレーク
実際にはもっと複雑な構成のログファイルから特定の操作を行ったIPアドレスを抽出する作業をしています。上の例文程度ならもっと効率的な方法があると思うし、僕がアホなだけでもっと簡単に処理できる方法は絶対にあるはず。
使ったもの(環境)
- Windows 10
- Mery Ver 2.6.7 (テキストエディタ)
下準備
Meryの機能を拡張するため、マクロを追加します。
- テキスト整形 -MeryWiki にアクセスし、『スターターパック』の項目にある『テキスト整形.zip』をダウンロード。
- ZIPファイルを展開し、ファイルふたつをMeryのインストールフォルダにある『Macros』フォルダにコピー。
- Meryを起動し、メニューの『マクロ』→『カスタマイズ』を開く。
- 『マクロのカスタイマイズ』というウインドウが開いたら『追加』をクリックし、保存した『テキスト整形.js』を開く。『OK』ボタンを押して『マクロのカスタイマイズ』ウインドウを閉じれば準備完了。
手順
1.特定の行だけを抽出
まずは『白米』と書かれた行のみを残し、その他の行を削除します。
- Meryでファイルを開き、テキストをすべて選択。
- メニューから『マクロ』→『テキスト整形』を選択。さらにコンテキストメニューみたいなものが表示されるので、『除去/削除』→『入力文字列を含む行を削除…』を選択。
- 表示されるウインドウに『白米』と入力して『OK』ボタンをクリック。
パンとかパスタの行が消えて、下のようになります。
2018年8月1日 白米[ふりかけ] のりたっぷりのふりかけでした 2018年8月4日 白米[納豆] 水戸土産の本場の納豆 2018年8月5日 白米[納豆] 二日連続の納豆ごはん 2018年8月7日 白米[鮭フレーク] ひと瓶800円、高級鮭フレーク
2.特定の文字列を抽出
各行の『白米』に続く角括弧内の文字だけを抽出します。
角括弧内の文字列は不規則なので、各行とも括弧開き以前と括弧閉じ以降の文字列を削除し、角括弧内の文字列のみを残す方法を取ります。
括弧開き以前を削除
メニューから『検索』→『置換』を選択。
『置換』ウインドウが開いたら『正規表現を使用する』にチェックを入れ、『検索する文字列』に下のとおり入力。
.*\[
最初のドットとアスタリスクは正規表現で「任意の文字が0個以上」という意味。4文字目は指定したい半角の角括弧開き。半角の角括弧は正規表現の処理でも使われる文字なので、今回は処理用ではなく文字として扱うよう、3文字目にバックスラッシュ(Windowsだと\マーク)を入れます。
『置換後の文字列』は空欄のまま、『すべて置換』をクリックします。結果は下のとおり。
ふりかけ] のりたっぷりのふりかけでした 納豆] 水戸土産の本場の納豆 納豆] 二日連続の納豆ごはん 鮭フレーク] ひと瓶800円、高級鮭フレーク
括弧閉じ以降を削除
やり方は括弧開き以前を削除したときと同じ。『検索する文字列』のみ下のとおり変更します。
\].*
これで「角括弧閉じ以降の0個以上の任意の文字列」という意味になります。『すべて置換』をクリックしたあとの結果は下のとおり。
ふりかけ 納豆 納豆 鮭フレーク
3.重複する文字列(同じ内容の行)を削除してひとつにする。
今回は統計をとるわけではなく単純に種類を知りたいだけなので、同じ内容の行がふたつ以上あった場合は削除し、ひとつだけ残します。操作は特定の行だけを抽出したときとほぼ同じ。
- テキストをすべて選択。
- メニューから『マクロ』→『テキスト整形』を選択。さらにコンテキストメニューみたいなものが表示されるので、『除去/削除』→『重複行を単一化』を選択。
例では2行あった『納豆』が1行のみになります。
ふりかけ 納豆 鮭フレーク
目的の形になったので以上で処理はおしまい。
その他所感
最初の方にも書いたけど今回抽出したかったはIPアドレス。正規表現でIPアドレスを検索する方法はなんとなく把握してる。
[0-9]+\.[0-9]+\.[0-9]+\.[0-9]+
検索はできるんだけどIPアドレス以外の部分を削除してIPアドレスだけを残す方法がわからない。なんかこう、サクッとできる方法はないもんか。
諸々含めてたぶんサクラエディタとかの方が簡単にできるんだろうけど、テキストエディタとしてはMeryの方が好き。Meryでなんとかしたい。
コメント
Meryの調査をしていたら、ここを見つけました。
マクロの勉強中ですが、以下で実現できましたので、報告させていただきます。
マクロライブラリにある「このファイルから検索(マッチする行)」をダウンロード
して変更しました。
よろしくお願いします。
// —————————————————————————–
// このファイルから検索(マッチする行)
//
// Copyright (c) Kuro. All Rights Reserved.
// www: https://www.haijin-boys.com/
// —————————————————————————–
//この範囲をコメントにした
//——
//var s = prompt(“検索”, “”);
//if (s == “”)
// Quit();
//——
//この範囲を追加した
//——
var s = “[0-9]+\.[0-9]+\.[0-9]+\.[0-9]+”;
//——
var r = new RegExp(s, “i”);
var s1 = “”;
if (document.selection.Text == “”)
document.selection.SelectAll();
var s1 = document.selection.Text.split(“\n”);
var s2 = new Array();
for (var i = 0; i < s1.length; i++) {
var s3 = r.exec(s1[i]);
if (s3)
//この範囲を追加した
//オリジナルは検索結果があれば、行を配列に追加している
//s3 には検索結果が入っているので、そのまま配列に追加している
//——
s2.push(s3);
//——
//この範囲をコメントにした
//——
// s2.push(s1[i]);
//——
}
document.selection.Text = s2.join("\n");
document.selection.StartOfDocument();
//以下のデータで確認しました
//——
//qqq
//aaa 192.168.1.1
//zzz
//bb [192.168.1.2] aaa
//aaa
//
//191.168.1.3
//
//zzz
//——
Meryの調査を行っていて、ここに来ました。
2週間前から使いはじめて、マクロの勉強中ですが
マクロライブラリにある「このファイルから検索(マッチする行)」を
変更すれば可能みたいです。
1:以下をコメントにしました
//var s = prompt(“検索”, “”);
//if (s == “”)
// Quit();
2:以下を追加しました
var s = “[0-9]+\.[0-9]+\.[0-9]+\.[0-9]+”;
3:以下を変更しました
s2.push(s1[i]);
を
s2.push(s3);
よろしくお願いします。
早速試してみたところ、問題なくIPアドレスだけを抽出することができました。
繰り返し行う作業なので時間を短縮できて助かります。
ありがとうございます!